'/%3E%3Cdefs%3E%3ClinearGradient id='paint0_linear' x1='0' y1='0' x2='0' y2='2160' gradientUnits='userSpaceOnUse'%3E%3Cstop/%3E%3Cstop offset='.1' stop-color='%23000' stop-opacity='0'/%3E%3Cstop offset='1' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3C/svg%3E%0A)

Maya: Intention-Based AI-powered browser
Orchestrating Intents with LLMs and Plugin Architecture
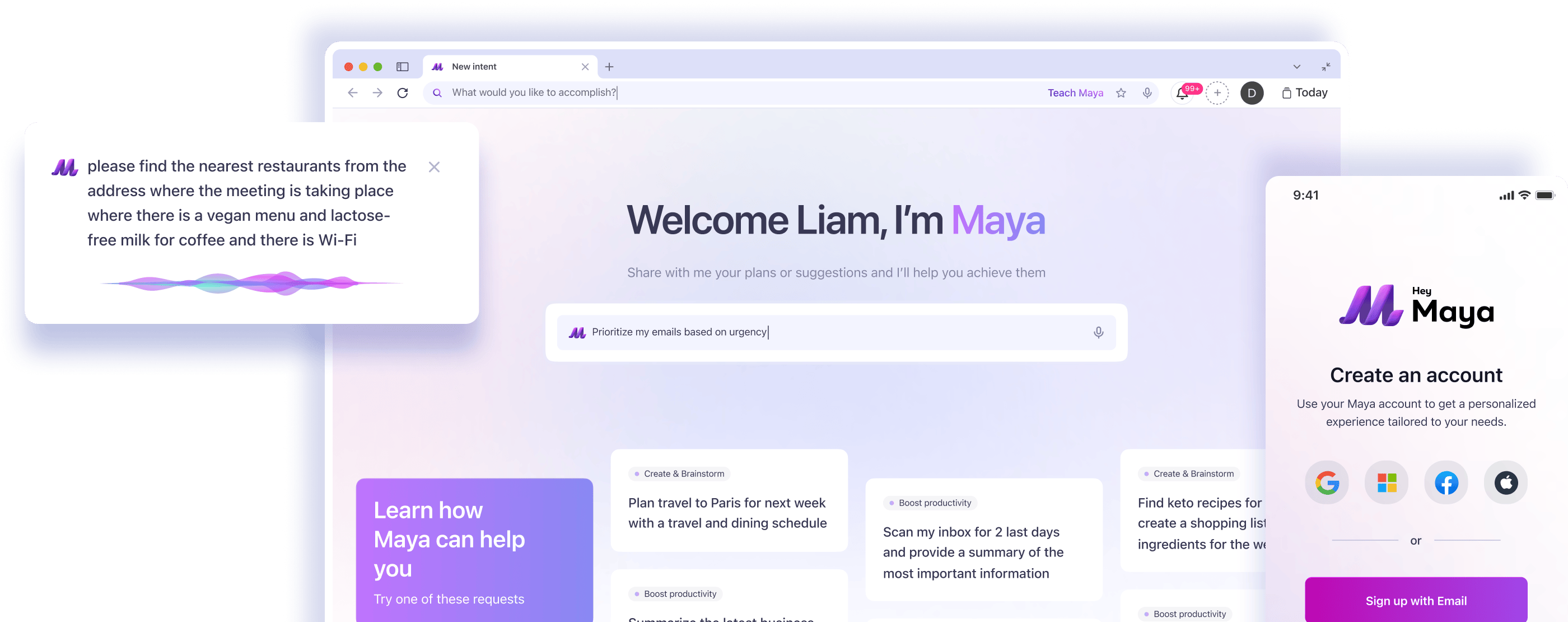
We developed Maya, an AI-powered desktop browser that replaces traditional app-based workflows with a seamless, intent-driven experience. Maya helps users complete complex tasks, like planning events, summarizing content, and managing schedules, by instantly interpreting natural language commands and surfacing the right tools. The system combines a plugin-based UI architecture, fine-tuned LLM models, real-time voice support, and a modular infrastructure optimized for responsiveness and privacy.
Download PDFBusiness Challenge
Modern knowledge workers face a fragmented digital experience that undermines focus and productivity. Maya was built to address several core challenges:
Fragmented Tool Ecosystem
Users rely on a patchwork of tools — email, reminders, notes, calendars — which operate in silos and require constant switching.Subscription Overload
Managing multiple AI tools often means juggling different accounts, interfaces, and paid subscriptions, complicating the experience and increasing cost.Shallow AI Responses
Traditional AI assistants lack contextual understanding and often provide irrelevant or incomplete responses.App-Centric Thinking
App-based thinking forces users to translate goals into tool-specific actions, which creates friction and cognitive overload.🎯 Key objectives
01Eliminate context switching by unifying core digital functions into a single, AI-powered platform.
02Shift from app-based interactions to goal-oriented flows, allowing users to express intent naturally.
03Deliver intelligent, context-aware assistance through integrated plugins for mail, files, calendar, tasks, and more.
04Ensure high usability and reliability through fast, accurate LLM-driven interactions and personalized suggestions.
Technical Challenge
To support this paradigm shift, we had to solve multiple hard engineering problems:
Intent Parsing
Convert open-ended voice or text input into structured intent objects with parameters.Dynamic Plugin Activation
Trigger and preload UI plugins in real time, based on predicted user intent, without user clicks.Privacy-Aware Session State
Maintain persistent context across different UI surfaces while respecting local storage boundaries and privacy constraints.Low-Latency Interaction
Achieve near-instant feedback (under 300ms) for both text input and streaming voice commands.Multi-Model Orchestration
Coordinate several LLMs and utility models across devices/services in parallel, ensuring no UI delays or race conditions.Frontend Responsiveness
Ensure that plugin surfaces remain interactive even when backend inference is pending or delayed.Architecture Overview

Backend
Monolithic NestJS core with isolated services for model inference and voice processing.

Long-Term Storage
PostgreSQL stores long-term user data and historical interactions.

Collaboration Engine
Fluid Framework ensures real-time sync between clients for collaborative context.

UI system
Plugin-based React interface with tokenized theming and lazy loading.

Session Context Management
Redis manages session-level context with automatic expiration.

Voice pipeline
Whisper handles live speech-to-text; transcripts pass directly into the intent classification stack.

Desktop Shell
Built with Electron to deliver a cross-platform native experience and deep OS integration.

Plugin Framework
Plugins register via a manifest-based SDK and are dynamically orchestrated through a unified runtime.
Main components
| Model Name | Architecture | Provider | Purpose | Input | Output | Usage Context |
|---|---|---|---|---|---|---|
Intent recognition | GPT-3.5 (fine-tuned) | OpenAI | Parse natural language into structured intent + steps | User prompt (text/voice transcription) | Intent type, parameters, plugin mapping | Core intent recognition and multi-step task decomposition |
Speech-to-text | Whisper (streaming) | OpenAI | Convert real-time speech to text | Audio stream (user voice input) | Clean text transcript | Voice-to-intent pipeline for user commands |
Wake Word Detection | Custom-trained CNN (via OpenWW) | In-house (OpenWW) | Detect wake word for voice activation | Streaming audio (PCM) | Boolean + audio slice | Triggers voice pipeline in real-time |
Summarizer | GPT-4 (prompt-based) | OpenAI | Summarize articles, emails, notes | Long-form text (articles, notes, email threads, etc.) | Short summary, metadata highlights | Plugin feature for text-heavy content |
Plugin reranker | Embedding reranker + LLM | In-house | Rerank plugin or action options from multiple candidates | List of plugin/action candidates + context | Ranked list of actions/plugins | Improves suggestion relevance after intent resolution |
Model Runtime Characteristics
| Model Name | Avg Inference Time | Retraining Frequency | Context Volume | Explainability | Real-Time Compatible |
|---|---|---|---|---|---|
Intent recognition | ~600 ms | Weekly | ~500 tokens + metadata | Limited (LLM) | Yes |
Speech-to-text | ~200 ms (streamed) | Not required | Audio stream | Not applicable (STT) | Yes |
Wake Word Detection | ~20 ms | Not required | Audio stream | Not applicable (STT) | Yes |
Summarizer | ~800 ms | Not required | ~1,000–2,000 tokens | Natural-language explanation (LLM) / Human-readable output | Yes |
Plugin reranker | ~150 ms | Weekly | Up to 10 candidates per prompt | Top-k scoring log | Yes |
Models we utilized



Fine-Tuning Summary
Base model: GPT-3.5-turbo
We selected GPT-3.5-turbo as the base model due to its balance between cost-efficiency, response speed, and instruction-following capabilities. It also supports OpenAI's fine-tuning API, which streamlined integration and evaluation.
Training Data
We prepared 1,000+ labeled examples across key plugin categories:
- Articles (e.g., summarize research papers)
- Video (e.g., retrieve and explain clips)
- Notes & Reminders (e.g., log a thought, set a task)
- Travel & Food (e.g., plan trips, generate meal plans)
- Files (e.g., search and open documents)

Objectives
We fine-tuned the model to accomplish three primary goals:
Decompose multi-part instructions
e.g., “Plan my week, suggest meals, and generate a shopping list” should be interpreted as three separate actions.Normalize time, location, and plugin references
So “this Friday,” “Paris,” or “my inbox” are transformed into structured parameters.Improve intent classification accuracy
Fine-tuning aimed to outperform zero-shot GPT-3.5 baselines for plugin selection.Challenges

Parameter hallucination
Occasionally, the model inserted incorrect or unsupported plugin arguments (e.g., empty date fields).
Validation loss instability
Due to class imbalance across plugin types, some categories lacked sufficient samples.
Edge case failures
Financial queries or abstract voice inputs (e.g., “what’s new in finance?”) didn’t always trigger the correct plugin or response type.Tuning pipeline:

Data augmentation via GPT-4 was used to generate high-quality synthetic examples.

We used the OpenAI Fine-tuning API for training and evaluation.

A feedback loop was established: weekly updates to the tuned-V1 model incorporated failed test cases and validation adjustments.
Our Solution
We delivered a robust AI-first desktop platform that unifies tools and interactions via dynamic plugin orchestration and intent-based routing. Here’s how:
Wake Word Detection Engine
To enable hands-free voice activation, we implemented a fully custom wake word detection system using the Open Wake Word framework. This setup ensured reliable, low-latency voice activation even under constrained desktop conditions.
Trained a proprietary neural model on diverse synthetic and noise-augmented audio samples.
Achieved detection latency as low as 20ms through audio buffering and optimized inference pipeline.
Avoided dependency on external vendors like Picovoice due to licensing and stability concerns.
Used C++ runtime fork for efficient model serving without cloud dependency.

Voice Command Engine
Voice commands are processed via a low-latency WebSocket-based pipeline.
Streaming ASR with partial hypotheses
Real-time feedback and rollback if misunderstood
Voice input triggers the same intent parsing as text
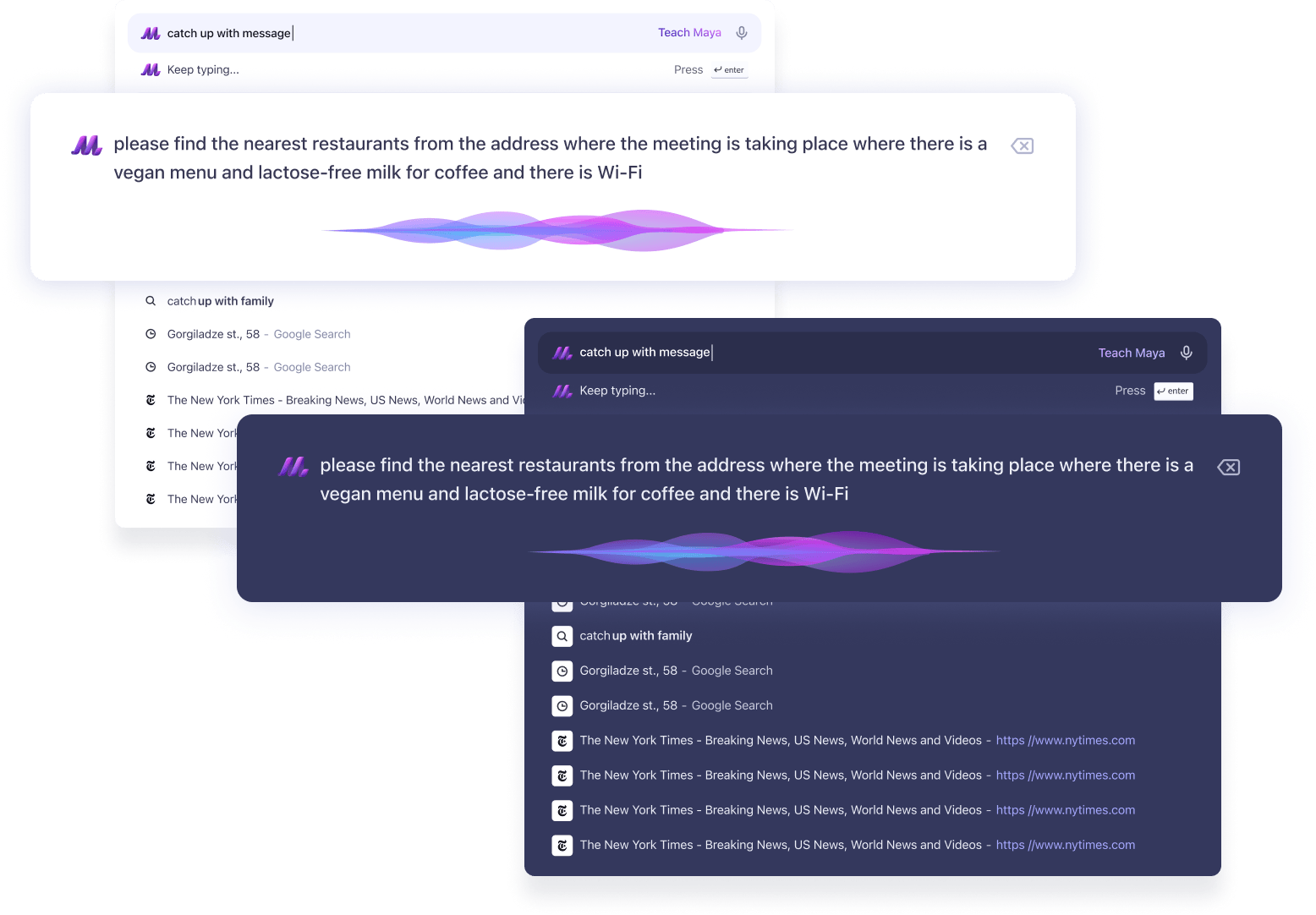
Goal-to-Interface Orchestration
Users don’t launch apps — they express goals. Maya parses user input (voice or text) and generates structured action trees, invoking relevant plugins and interfaces to accomplish the goal.
JSON-based action definitions generated via LLM
Intent router supports both LLM and fallback rules
Supports compound flows (e.g., “Plan trip + create checklist + send invites”)
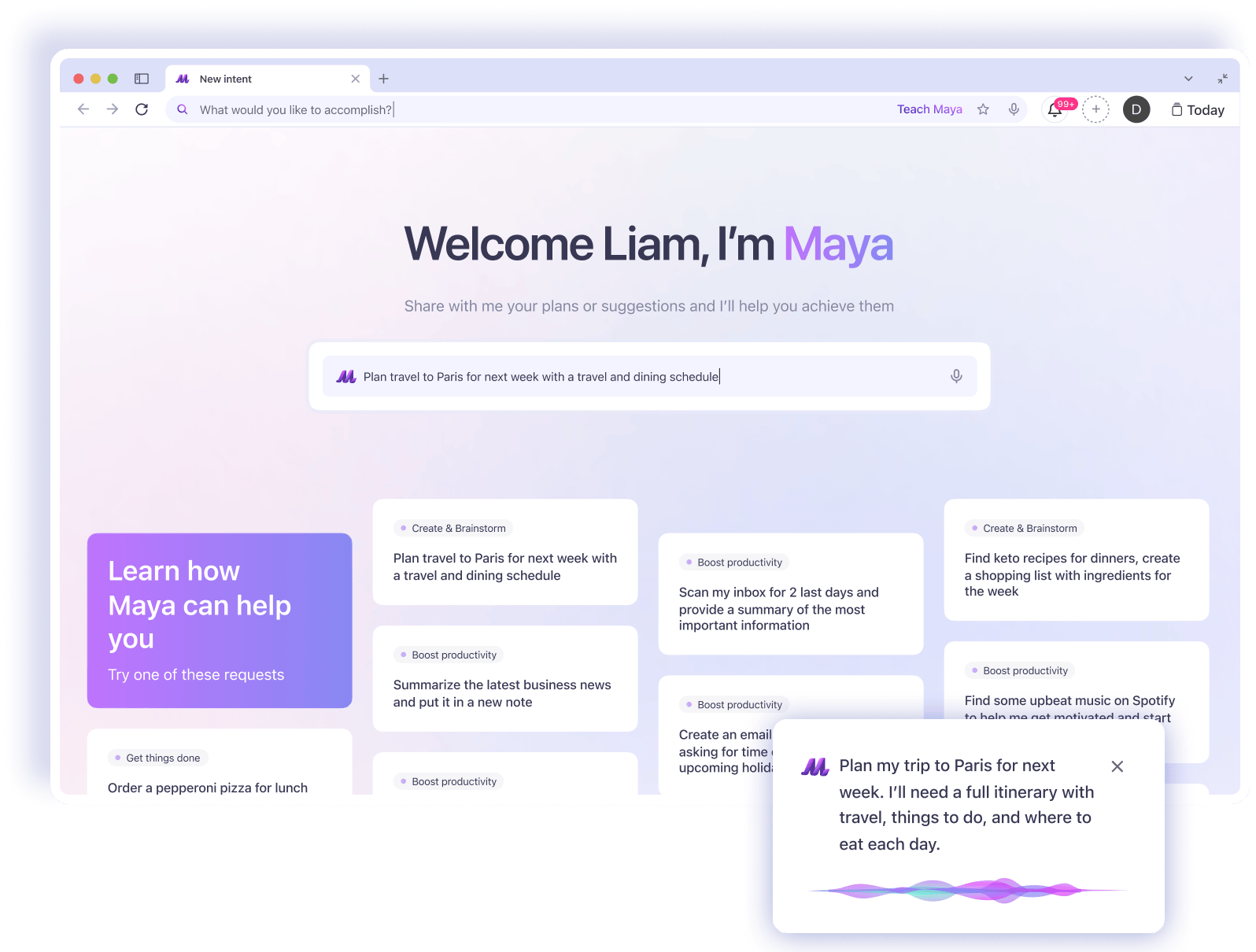
Plugin-Based Architecture
Maya uses a modular plugin framework to support native tools like Email, Notes, Calendar, and third-party integrations.
Plugins are registered dynamically and expose capabilities via a manifest
Execution is orchestrated by a centralized PluginManager
Built-in error boundaries and timeouts ensure system resilience
Dynamic Multi-Plugin Flows
Maya decomposes complex user goals into sequential actions across multiple plugins—without requiring the user to manually orchestrate them. The system automatically invokes the right combination of modules to complete the task.
Intent decomposition supports chained plugin flows (e.g., Calendar → Notes → Files)
Plugins are invoked in order, passing shared context and data
UI adapts dynamically as each plugin contributes to the goal
Built-in fallback for incomplete or ambiguous input
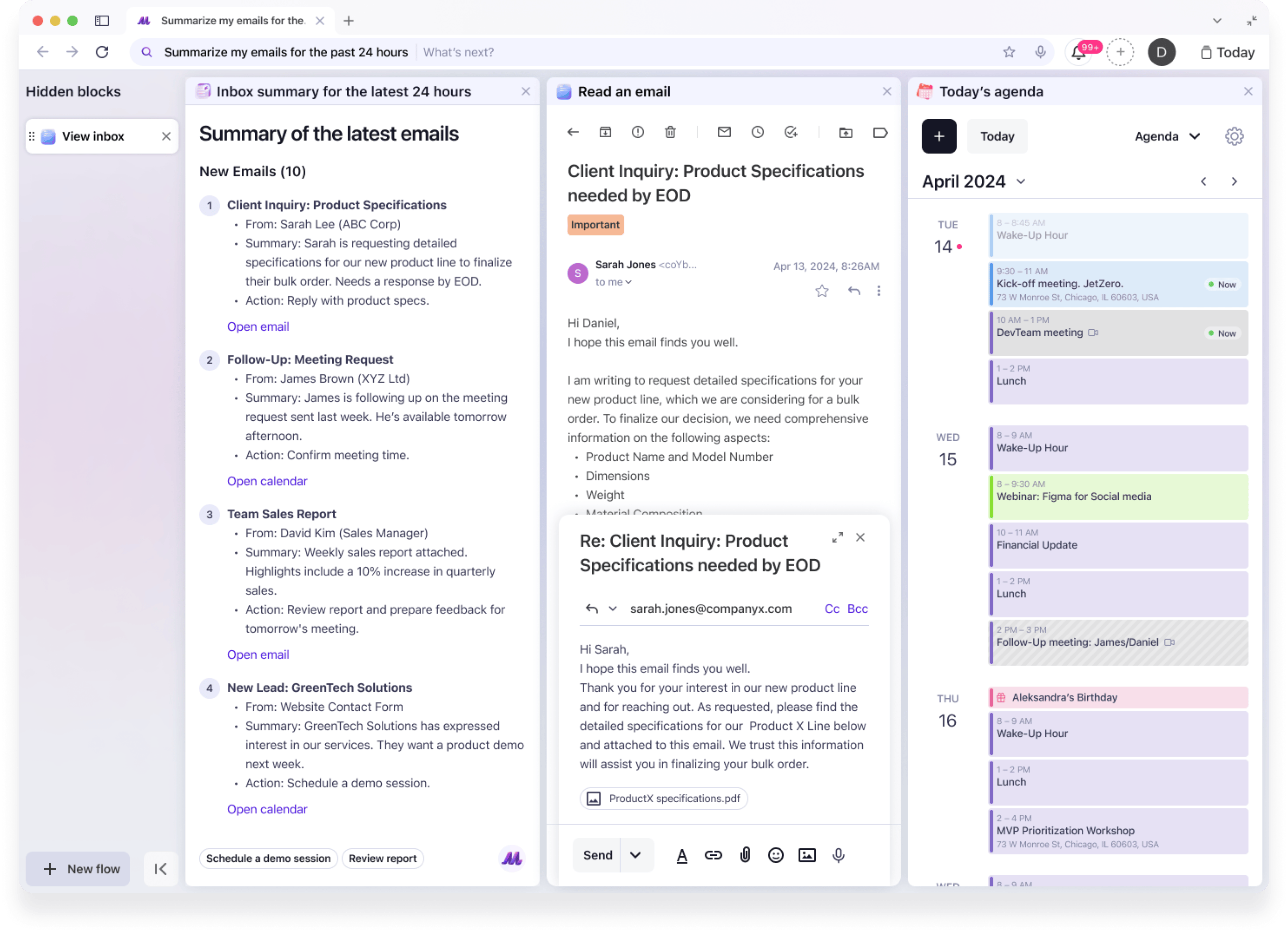
Persistent Context Memory
User preferences, past intents, and plugin outputs are cached for continuity across sessions.
Redis used for short-term intent chaining
PostgreSQL stores longer-term preferences and records
Each plugin can declare required context for rehydration
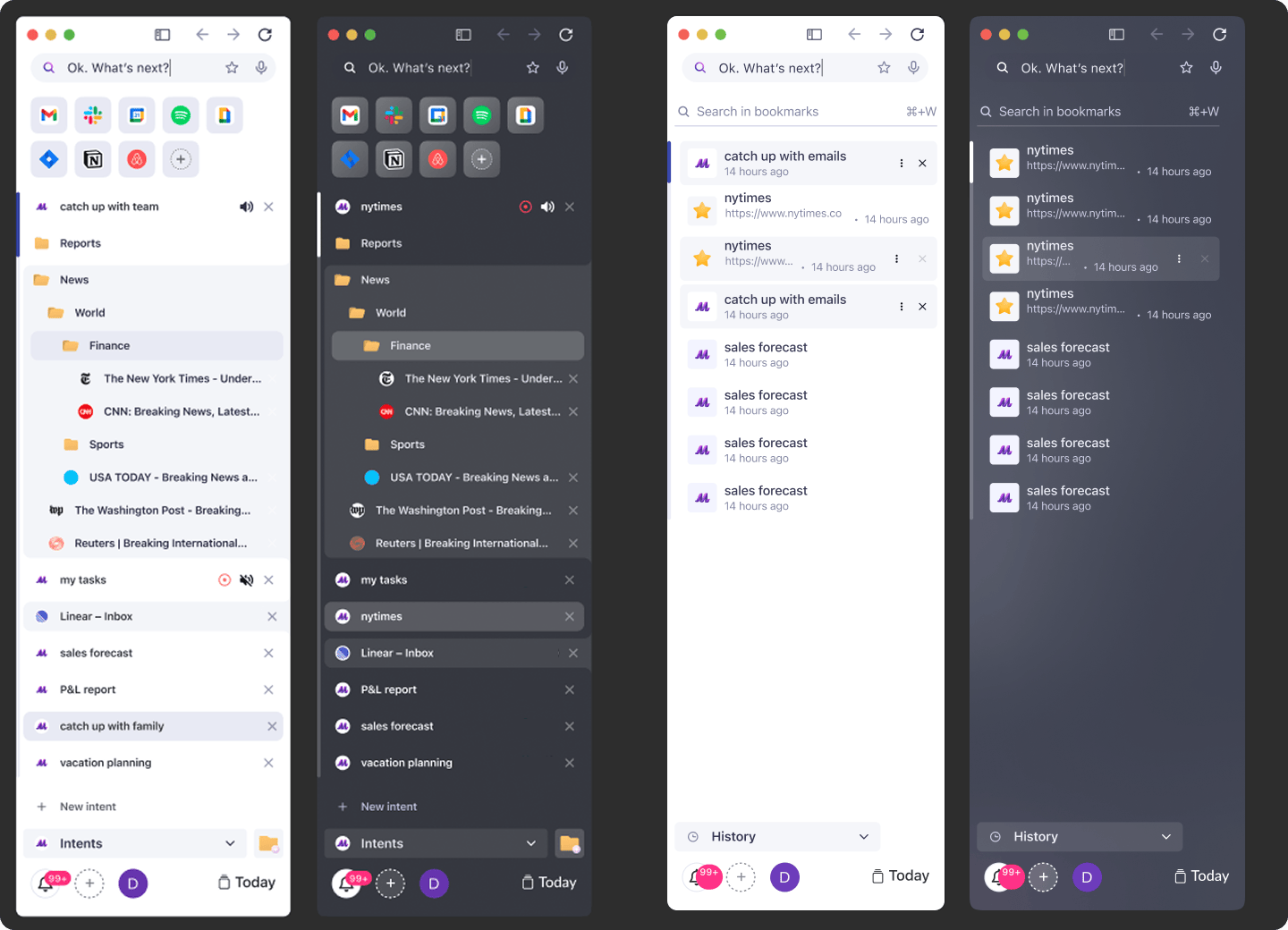
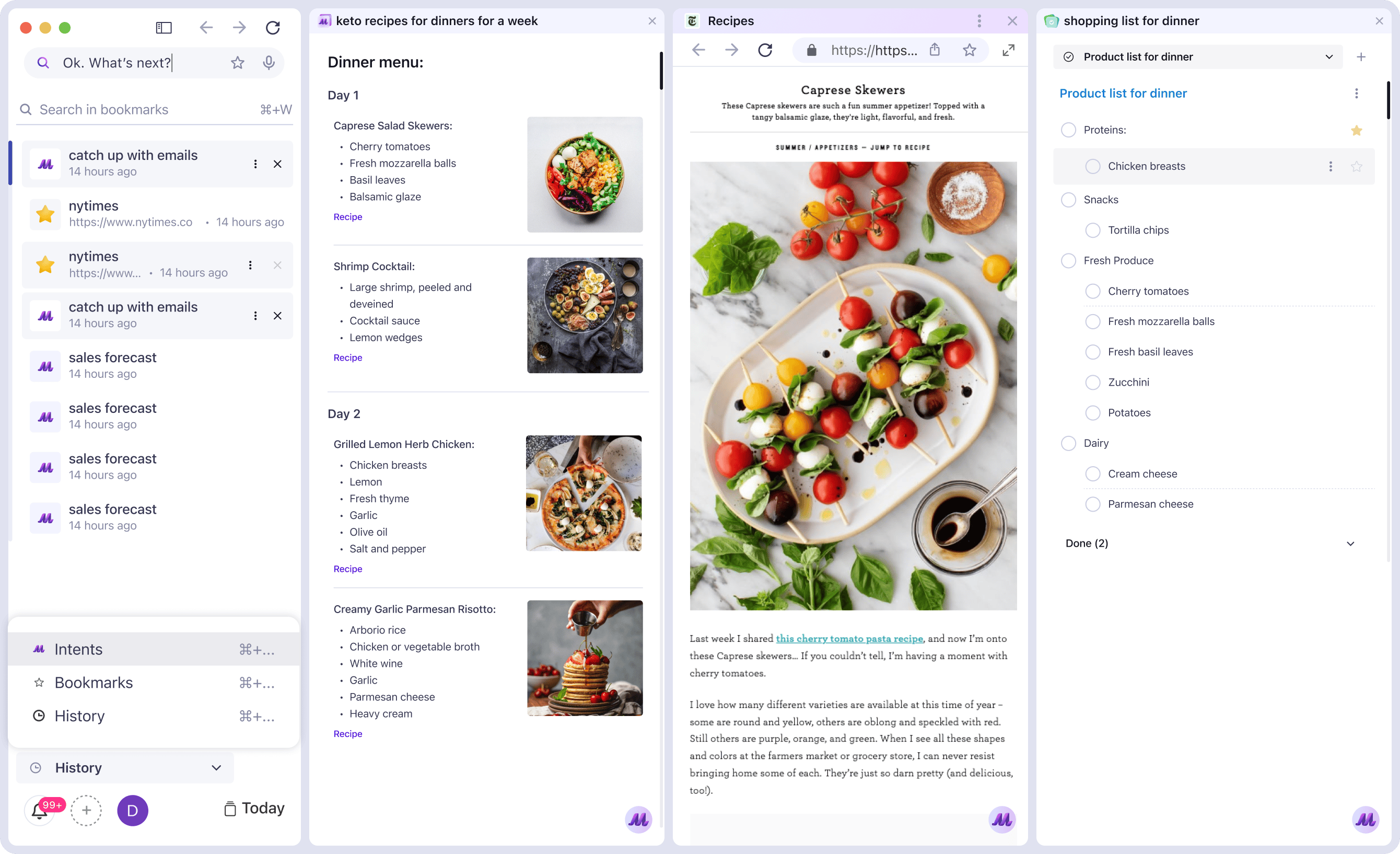
Impact
85%+ scenarios completed without fallback
Most user goals were handled end-to-end without manual input correction.<300ms voice response latency
Real-time speech interactions felt seamless and responsive.3+ tools replaced in user workflows
Early adopters reported dropping separate apps for email, notes, and planning.40% faster load in predicted flows
Plugin preloading based on intent cut wait times in common tasks.100% cross-device deployment readiness
Architecture scaled smoothly and supported compliance-heavy environments.


Get in touch
To discuss your development needs
Attach files
Send me an NDA
Attach files
or drag & drop files here
Send me a SiliconMint NDA
Send